
Голосовой ввод и распознавание речи: мой путь через 5+ приложений
В прошлом году я смотрел ролик Тиаго Форте — создателя концепции Second Brain — где он что-то делал при помощи Claude и показывал утилиту для голосового набора под названием WisprFlow. Она считывала его речь, форматировала, расставляла знаки препинания — прям вообще супер работало.
Сразу загорелся: надо пробовать.
С того момента прошло полгода. За это время — 5+ приложений, один pull request в open source (приняли в main!), бенчмарк двух моделей Whisper и промпт, который починил пунктуацию в 99% случаев. Эта статья — про весь путь. И про то, как те же модели работают для транскрибации записей.
Актуально на март 2026 года. Модели и приложения в этой области обновляются быстро — проверяйте версии.
Статья длинная, с техническими деталями. Если нужен быстрый ответ «что поставить» — в конце есть сводная таблица. Но если интересно, как одна модель пишет «research» латиницей, а другая — «ресёрч» кириллицей, и какая из них на самом деле лучше для русского с вкраплениями английского — читайте по порядку.
Зачем голосовой набор, если быстро печатаешь
Я печатаю бегло и по-русски, и по-английски. Но голосом мы говорим со скоростью 150-180 слов в минуту — а это в 2-3 раза быстрее, чем набираем текст.
Крупнейшее исследование скорости набора (Aalto University, 168 000 участников) показало среднюю скорость 52 слова в минуту (WPM). IT-специалисты печатают быстрее, в среднем около 70 WPM. Зак Прозер, developer advocate в Pinecone, замерил конкретно: 90 WPM печатью, 179 голосом. За год надиктовал 180 000 слов в 36 приложениях.

Конечно, сырая скорость — не всё. После диктовки текст нужно проверить и поправить. Но вот что важно: насколько много правок — зависит от задачи. Если ты диктуешь медицинскую документацию, где каждое слово на вес золота, правки съедают значительную часть выигрыша. Но если ты диктуешь промпт в LLM, сообщение в Telegram или черновик поста — текст не должен быть идеальным. Нейросеть поймёт. Собеседник поймёт. Правок минимум.
Исследования подтверждают: диктовка даёт максимальный выигрыш именно на линейном повествовательном тексте — потоке сознания, email, заметках. На структурированном вводе (формы, шаблоны, код) клавиатура не хуже или даже лучше. А мои основные сценарии — как раз линейный текст: объяснить задачу нейросети на два абзаца, надиктовать длинное сообщение, проговорить идею для статьи.
С появлением вайб-кодинга голосовой набор стал ещё актуальнее. Andrej Karpathy — один из создателей OpenAI, бывший директор AI в Tesla — написал про свой воркфлоу с Cursor:
I just talk to Composer with SuperWhisper so I barely even touch the keyboard
Andrej Karpathy
Когда ты работаешь с Cursor или Claude Code, большая часть времени уходит на объяснение задачи. Тебе нужно сослаться на файл, описать баг, назвать функцию — и всё это на смеси русского и английского. Если модель распознавания понимает оба языка одновременно — голосовой набор для этого идеален.
А что есть бесплатно из коробки?
Прежде чем тратить деньги, я проверил, что уже есть.
iOS dictation. На айфоне и маке есть встроенный голосовой набор. Слова ловит неплохо, но набирает по одному — получается бесконечный поток сознания, где только первое слово с большой буквы, а дальше ни единой запятой. Можно расставлять знаки препинания голосом — говоришь «точка», «тире», «запятая» — но это, конечно, не то.
Voice Mode в нейросетях. Когда ты общаешься с нейросетью голосом и она голосом отвечает. Это здесь вообще не рассматриваем — нам нужен голосовой набор текста, а не голосовой чат.
Claude. На конец марта 2026 года голосовой ввод в приложении Claude на Windows и Mac работает только на английском. На iPhone — работает с русским, но качество так себе, иногда падает. Видно, что эта функция не в фокусе — по крайней мере для русского языка.
ChatGPT. А вот тут хорошо. На всех платформах — Windows, Mac, iPhone — отлично расшифровывает русскую речь. Вероятно, потому что именно OpenAI в 2022 году разработала семейство моделей Whisper — на сегодня стандарт качества в распознавании речи.
Windows. Формально Win+H поддерживает русский в Windows 11, но качество на уровне «для коротких фраз сойдёт». Жутко неудобный интерфейс, и мой любимый прикол: если язык раскладки английский, то и голосовой набор оно тоже будет пытаться делать на английском, отказываясь понимать русский. Для серьёзной диктовки — мимо. Офлайн-распознавание русского в Windows не поддерживается вообще. А Windows — моя основная система, домашняя рабочая станция.
Итого: из бесплатного более-менее адекватно работает только голосовой ввод в ChatGPT. Но если вы, как и я, используете другие нейросети — вам нужен отдельный инструмент.
WisprFlow и SpeakFlow: платные облачные решения
Вернёмся к WhisperFlow, с которого всё началось.

Я установил его, там был бесплатный режим — до 2 000 слов в месяц. За несколько недель понял: это реально тема, реально ускоряет. Уже тогда активно общался с нейросетками, и голосовой набор прям зашёл.
Захотел купить подписку. Цена: $15 в месяц, $144 в год. Потом я узнал, что подписку можно купить через российский App Store с региональным прайсингом — рекомендую всегда проверять: 750 ₽ в месяц вместо $15, 7 200 ₽ в год вместо $144. При курсе 80 ₽ за доллар это меньше 10 долларов вместо 15 и 90 вместо 144. Плюс не нужен геморрой с зарубежными картами.
Но WisprFlow начал подводить. Самая фрустрирующая проблема — иногда текст приходил вообще без единого знака препинания. Надиктовываешь минуту — получаешь гигантский абзац неразмеченного текста. У WisprFlow есть фичи, которые подстраиваются под приложение, в котором ты диктуешь. Диктую в терминал — всё идеально размечено. Диктую в Claude Desktop — без единой запятой. И это было главное место, где мне нужен голосовой набор.
Тут можно сказать: «Да какая разница, LLM и так поймёт». На самом деле — нет, и дальше покажу конкретные цифры.
Помимо пунктуации, приложение после долгой работы в фоне начинало дико грузить процессор и вешать систему. Я писал баг-репорты — но за пару месяцев ничего не изменилось. Начал искать альтернативы.
Наткнулся на российский проект SpeakFlow. Маленький независимый разработчик, увидел где-то в Telegram — кто-то продвигал страницу на ProductRadar. Цена: 690 ₽ в месяц, оплата российской картой. На тот момент я ещё не знал про App Store фишку, так что SpeakFlow выглядел почти вдвое дешевле WisprFlow.
Скажу честно: немного стрёмно было ставить приложение без цифровой подписи от маленького разработчика. Плюс — ничего плохого не имею в виду, но я как-то исторически предпочитаю свою персуху сливать компаниям, которые подальше от меня находятся.
Поставил, попробовал. Как будто с русским чуть получше — разработчик русский, видимо, докрутки делал. Были какие-то модели под авторскими названиями — непрозрачно, что внутри и чем отличаются. По большей части делали примерно одно и то же.
И те же грабли: иногда пропадала пунктуация, memory leaks, подвисания. Некоторые апдейты всё ломали. Переписка с поддержкой ещё больше напрягла — тут и деанонимизация происходит: пишешь со своего телеграм-аккаунта, и можно связать аккаунт с твоей системой.
Между делом попробовал ещё Voicy — что-то среднее между WisprFlow и SpeakFlow, но к результату тоже были вопросы. Были варианты чисто под Mac, типа MacWhisper, но у меня основная машина на Windows, и мне нужно решение под обе платформы.
Ещё один заметный игрок — Aqua Voice ($10/мес, выпускник Y Combinator): они обучили собственную модель Avalon специально на dev-контексте — CLI, IDE, технические термины. На английском впечатляет, но русский пока работает на стандартном движке, а в рунете продукт практически неизвестен.
Ключевое: и WisprFlow, и SpeakFlow — облачные. Всё, что ты надиктовываешь, отправляется на сервер для обработки. А мы сейчас общаемся с LLM о самом разном — рабочие детали, личные вещи, иногда достаточно сокровенное. Чем меньше посредников в этой цепочке, тем лучше. В идеале хотелось бы, чтобы всё оставалось на моей машине.
Handy: open source и свобода выбора
Потом я наткнулся — тоже где-то в Telegram — на open-source проект Handy. По сути, то же самое: голосовой набор, транскрибация речи в текст. Но бесплатно, полностью локально — ничего никуда не отправляется, всё на твоей машине. Плюс можно выбирать из разных моделей распознавания.

Я такой: «Вау! Это можно не платить 700 ₽ в месяц? И делать всё локально, и не переживать за приватность?» Маленькая оговорка: я на 95% уверен, что со SpeakFlow в плане приватности всё в порядке. Но, как говорится, выживают только параноики.
Handy работает и на Windows, и на Mac. Внутри — практически все основные модели. Я раньше сталкивался с Whisper, когда собирал себе скрипт для транскрибации видео — скачал какую-то модель, прикрутил, работало. Но не разбирался, какие модели бывают и чем отличаются. И вот тут впервые вник.
Из того, что давало нормальную скорость — модель Parakeet V3 от NVIDIA. Но у неё был главный для меня вопрос: микс языков. Когда вплетаешь английские слова в русскую речь — а при общении с LLM это неизбежно — Parakeet справлялся так себе.
Лучший результат по качеству давало семейство Whisper от OpenAI. У них есть модели по размеру — самая большая называется Whisper Large, 1,55 миллиарда параметров. Она давала лучший результат по всем фронтам: знаки препинания, микс языков, заглавные буквы. Русские слова — русскими буквами, английские — английскими. Супер.
Одна проблема: по умолчанию все эти модели работают на процессоре (CPU). И если лёгкие модели на CPU тянут нормально, то Whisper Large приходилось мучительно долго ждать. По моим замерам на десктопном i5-13600K — минута речи, почти две минуты обработки. Транскрипция медленнее, чем сама запись.
И тут надо сказать про скорость. Качество распознавания — это половина дела. Вторая половина — насколько быстро текст появляется на экране. Если ты наговорил 20 секунд и потом ждёшь — весь кайф убивается. В идеале ты хочешь, чтобы 20 секунд речи расшифровывались за секунду. Это называется real-time x20 — в 20 раз быстрее реального времени. Тогда вставка ощущается как моментальная.
Модели поменьше — Whisper Turbo, Medium — были быстрее, но качество падало. На миксе языков уже приближалось к Parakeet, а Parakeet был ещё и быстрее. В итоге бо́льшую часть времени я проводил на Parakeet как на компромиссе.
А потом в разговоре с Claude выяснилось, что эти модели можно загружать в видеопамять и ускорять через видеокарту. У NVIDIA есть специальная технология — CUDA — которая для этого идеально подходит. В Handy GPU-акселерация была, но через Vulkan — универсальный стандарт, который для карт NVIDIA обычно менее эффективен, чем родная CUDA. Я так понимаю, автор Handy разрабатывает на Mac, где NVIDIA нет.
Мне нужен был софт с CUDA.
OpenWhispr и GPU-ускорение: когда всё полетело
Я убил несколько часов, колупаясь в заброшенных GitHub-репозиториях — не всегда сразу понимая, что они не обновлялись полтора года. Какие-то решения с CUDA были платные, какие-то с разовой оплатой — хотелось бы без этого.
И потом я нашёл OpenWhispr.
Open source, 2 100+ звёзд на GitHub, активная разработка. Бизнес-модель простая: бесплатно, если модели крутятся у тебя локально. Или подписка — если хочешь облачную обработку. Можно подключить свои API-ключи от LLM-провайдеров.
Главное — CUDA из коробки.
Whisper Large на моей RTX 3080 — уже не новая, но всё ещё серьёзная карта — стал работать значительно быстрее — сопоставимо с Parakeet по скорости, но при гораздо лучшем качестве. Всё на месте: английские слова латиницей, пунктуация, заглавные буквы.

Приложение активно развивается, и в нём есть баги — как в любом живом проекте. Но оно опенсорсное, и это меняет всё. Можно починить баг самостоятельно. Или сделать фичу, которая нужна только тебе. Именно благодаря OpenWhispr я на практике понял силу open source — и отправил свой первый в жизни pull request. Его приняли в main. На момент написания у проекта 302 форка и 2 100+ звёзд.
Моё текущее решение — OpenWhispr + Whisper Large. На NVIDIA с CUDA это летает. На Mac с Apple Silicon тоже хорошо: на моём MacBook Pro с M4 Pro (14-ядерный) — более чем достаточная скорость для комфортной работы. На обычном M4 — уже на грани. M5 и M5 Pro потянут наверняка, M3 Pro — скорее да, но он всего на 5% мощнее обычного M4 в бенчмарках, так что гарантировать не берусь.
Если у вас AMD — путь есть, но менее гладкий. Лучший вариант — приложения на базе whisper.cpp с Vulkan-ускорением (например, Handy). Работает на большинстве AMD-карт без специальных драйверов. Vulkan — универсальный стандарт, поэтому и на AMD, и на NVIDIA будет работать. А на новых RTX 50xx Vulkan ещё и быстрее CUDA — подробнее в секции бенчмарка ниже.
Но одна проблема оставалась и здесь: нет-нет, да и проскакивала транскрипция вообще без знаков препинания. Причём проблема эта есть и на английском языке.
Пунктуация: больше, чем красота
Можно сказать: «Да ладно, LLM и так поймёт текст без запятых». Поймёт. Но хуже.
И это не субъективное ощущение — есть исследования с конкретными цифрами.
Работа Sclar et al., опубликованная на ICLR 2024, показала: разница в точности ответа модели может достигать 76 процентных пунктов — то есть на одной и той же задаче модель может выдать 90% accuracy или 14%, просто от изменения форматирования промпта. Не содержания, а пробелов, пунктуации, разделителей.
Ещё интереснее результаты LLM-Microscope (NAACL 2025): оказалось, что знаки препинания работают как attention sinks внутри трансформеров. Модель буквально использует их для обработки контекста. Цитата из статьи: «Пунктуация, которую люди считают незначительной, играет удивительно активную и сложную роль внутри этих моделей».
А исследование Rev показало, что текст без пунктуации хуже для понимания, чем текст с 15-20% ошибок в словах. То есть лучше перепутать каждое пятое слово, чем убрать все запятые.
Все три главных AI-лаборатории — OpenAI, Anthropic, Google — в своих документациях рекомендуют структурированные, хорошо отформатированные промпты.
Вывод для голосового набора прямой: качество пунктуации в STT-модели напрямую влияет на качество ответов нейросети. Запятые и точки в вашем тексте — реальный перформанс взаимодействия с LLM.

Промпт, который починил пунктуацию
Проблема с пропадающей пунктуацией преследовала меня с самого первого приложения. В WisprFlow, в SpeakFlow, и в OpenWhispr — везде нет-нет, да и прилетал текст без единого знака препинания.
В OpenWhispr есть возможность подключить вторую модель для пост-обработки текста — text cleanup. Я попробовал: например, Qwen3 4B неплохо расставляет знаки препинания, если на вход пришёл текст без них. Но на моей 3080 Whisper Large уже занимал значительную часть видеопамяти, а вторая модель съедала всё остальное — 10 ГБ VRAM забиты под завязку, вся видеокарта отведена под распознавание речи и ничего больше делать нельзя. Плюс обработка последовательная: сначала Whisper Large расшифровывает аудио, потом передаёт текст в Qwen, и ты ждёшь, пока обе модели отработают по очереди. Текст на выходе лучше, но ощутимая задержка убивает интерактивность — голосовой набор перестаёт ощущаться как поток.
И тут я нашёл решение проще и элегантнее — без второй модели вообще.
В Whisper можно прокинуть текстовый промпт. Но он работает не как промпт к обычной нейросети. Модель не нуждается в инструкциях — у неё одна задача: превращать аудио в текст. Промпт работает как «прогрев»: мы показываем модели желаемый образ результата.
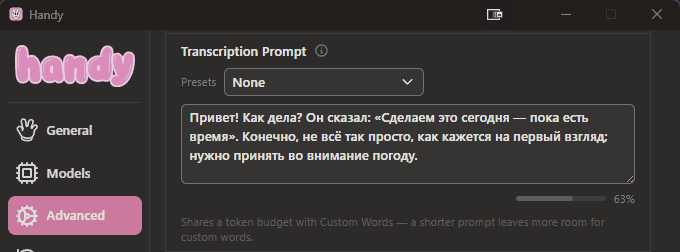
Вот промпт, который даёт мне пунктуацию в 99%+ случаев:
Привет! Как дела? Он сказал: «Сделаем это сегодня — пока есть время». Конечно, не всё так просто; нужно учесть погоду.
Смысл текста совершенно не важен. Важно, что в этом коротком фрагменте использованы все основные знаки препинания: запятая, точка, вопросительный знак, восклицательный знак, двоеточие, кавычки-ёлочки, тире, точка с запятой.
Работает просто супер. Вторая модель для text cleanup больше не нужна.
В стандартном интерфейсе OpenWhispr поля для кастомного промпта пока нет — я добавил его в своём форке и отправил pull request. Параллельно сделал то же самое для Handy. Оба PR’а пока в ожидании, в main не попали.
Пока колупал, дошёл до главного вывода: промпт не должен быть захардкожен. Это должно быть поле в настройках, с пресетом на каждый поддерживаемый язык — а пользователь может изменить текст, если хочется. Именно так я это и предложил в обоих PR’ах.
Почему так. Даже мой «99% промпт» не идеален: я заметил, что в каких-то версиях пресета кавычки-ёлочки (« ») иногда дают побочный эффект — модель воспринимает их как маркер прямой речи и начинает упаковывать в неё то, что прямой речью не является. Иногда это ок. Иногда — нет. Кому-то ёлочки вообще не нужны. Хардкод одного варианта для всех — неправильный ответ; поле, где можно поэкспериментировать — правильный.
Единственная оставшаяся неприятность — Whisper иногда ловит петлю: спотыкается на слове, расшифровывает его неправильно, и дальше начинает повторять по кругу. Это задокументированная проблема модели — встречается примерно в 1,4% сегментов. Исследователи уже нашли способы снизить её на 80%+, так что думаю, скоро это дойдёт до приложений. У меня тоже есть несколько приёмов, которые помогают, но не на 100%. Если интересно — обсудим в комментариях.
Turbo vs Large v3: мой бенчмарк
Но прежде чем перейти к цифрам — пара слов о том, как вообще устроены модели распознавания речи. Без этого результаты бенчмарка будут просто числами.
Whisper Large v3 от OpenAI — подход «в лоб». Гигантская нейросеть на 1,55 миллиарда параметров, обученная на 680 тысячах часов аудио на 100+ языках. Архитектура классическая: энкодер «слушает» звук, декодер «пишет» текст токен за токеном — как GPT пишет ответ в чате. 32 слоя декодера — много вычислений на каждую секунду речи. Швейцарский нож: умеет всё, но не самый быстрый.
GigaAM v3 от Сбера — противоположность. Всего 220 миллионов параметров (в 7 раз меньше), зато обучен исключительно на русском — 700 тысяч часов русской речи. Это скальпель, заточенный под одну задачу. Плюс другая архитектура: вместо «энкодер думает, потом декодер пишет» используется RNNT, который выдаёт текст потоково, по мере поступления звука. Маленькая модель + потоковая архитектура = результат быстрее, чем аудио успевает проиграться.
Whisper Turbo — попытка OpenAI догнать по скорости, не переписывая всё с нуля. Берём обученный Large v3, оставляем энкодер как есть, а декодер ужимаем с 32 слоёв до 4 и дообучаем. (Часто это называют дистилляцией, но сами OpenAI уточняют, что в строгом смысле — нет: «учителя и ученика» здесь нет, декодер просто урезали и дотюнили.) Результат: 809 миллионов параметров; насколько именно быстрее — зависит от реализации: на графиках OpenAI ускорение доходит до 6–7×, на типичном десктопе через whisper.cpp скромнее (в моём замере около 2,5×). Грубо — в 3–6 раз. Качество падает совсем немного. Если Large — это профессор, который тщательно обдумывает каждое слово, то Turbo — тот же профессор, но отвечающий навскидку. Обычно попадает, но иногда упрощает.
Когда я впервые попробовал Turbo — ещё в процессе использования, до всякого ресёрча — мне показалось, что результат хуже, чем у Large. Чуть больше ошибок в английских словах, чуть менее аккуратная пунктуация. Я целенаправленно двигался в сторону Large: настраивал CUDA, искал правильный софт, добивался промпта для пунктуации.
А потом, уже готовя эту статью, наткнулся на бенчмарк faster-whisper, который показывал, что Turbo лучше Large v3 на русском: 7,7% WER против 7,9%. Контринтуитивный результат. Я такой: «Блин, может я зря столько времени убил на Large?»
Попробовал Turbo снова — и офигел от скорости. В 3-4 раза быстрее, чем Large v3, который у меня и так уже работал без задержки. Абзацами текст моментально выстреливает. На секунду реально подумал: зачем я всё это делал?
Но потом решил проверить по-нормальному. Взял два аудиофайла и каждый по 10 раз прогнал через обе модели. Сделал это дважды: сначала без пунктуационного промпта, потом с ним. К этому моменту я уже проапгрейдился с RTX 3080 на RTX 5070 Ti с 16 ГБ VRAM — так что бенчмарк на ней.
| Сказано | Turbo | Large v3 |
|---|---|---|
| Telegram | Telegram | Телеграме |
| research | ресёрч | research |
| Gemini | джемина и | Gemini |
| 5070 Ti | 5070 ти | 5070 Ti |

Large v3 пишет английские слова латиницей, а заимствования, которые в русском склоняются, адаптирует: «в Телеграме» вместо «в Telegram» — и это скорее плюс. Ещё Large v3 расставляет кавычки-ёлочки и многоточия там, где Turbo их теряет. Turbo чаще транслитерирует английские слова в кириллицу и упрощает пунктуацию.
Вот тут и выяснилось, что бенчмарк faster-whisper не врал — но и мой первоначальный опыт тоже не обманывал. Вероятно, разница в датасетах: бенчмарк был на чистом русском, а мой кейс — русский с вкраплениями английского. На чистом русском Turbo действительно не хуже. Но стоит добавить английские термины — и Large v3 заметно точнее.
Ещё один инсайт из цифр: скорость обработки зависит не столько от длины аудио, сколько от того, что и как вы говорите. Два файла с одинаковым текстом, но разной длительностью (37 и 57 секунд) дали одинаковое время обработки — длина записи не повлияла. А вот сложность контента и манера речи влияют: уверенная диктовка обрабатывается быстрее, чем перечитка того же текста с паузами и придыханиями. Large с его 32-слойным декодером чувствительнее к этому, чем Turbo с 4 слоями.
Может показаться, что разница между моделями невелика — ну ошиблась одна на пару слов больше другой. Но на практике это часто разница между текстом, в который нужно лезть и править, и текстом, который можно отправить как есть. Когда инструмент раз за разом выдаёт результат без единой ошибки — это совсем другое ощущение от работы. Голосовой набор становится потоком, а не чередованием диктовки и редактуры.
Итог: если железо позволяет и задержка Large v3 не напрягает — нет причин выбирать Turbo. Качество выше, особенно на миксе языков. Если же Large на вашем GPU работает с заметной задержкой — Turbo отличная альтернатива, в 3-4 раза быстрее при сопоставимом качестве на чистом русском. Я остаюсь на Large v3.
Под капотом: CPU, CUDA и Vulkan
Все числа выше — на видеокарте. А что если GPU нет?
Я прогнал отдельный бенчмарк: тот же Whisper Large v3, те же файлы, но на процессоре. i5-13600K — нормальный десктопный процессор, не какой-нибудь Celeron. Результат: 69 секунд аудио обрабатывались почти 2 минуты. CPU в 30-60 раз медленнее GPU на той же задаче. Без видеокарты голосовой ввод с Whisper Large — это боль.
Второй неожиданный результат — про саму видеокарту. Выше я писал, что Vulkan «менее эффективен, чем CUDA на NVIDIA». На моей предыдущей RTX 3080 (Ampere) так и было — собственно, ради CUDA я и перешёл с Handy на OpenWhispr. По данным сообщества ggml, на Ampere CUDA выигрывает у Vulkan 20-30%.
Но на моей новой RTX 5070 Ti (архитектура Blackwell) всё наоборот: Vulkan стабильно на ~50% быстрее CUDA. Я собрал оба бэкенда из одних исходников whisper.cpp v1.8.4, прогнал каждый файл по три раза — разница воспроизводимая, не артефакт.
Причина: CUDA-поддержка Blackwell (sm_120) ещё сырая. Это подтверждают и другие проекты — например, faster-whisper на RTX 5070 Ti работает на 10% медленнее, чем на предыдущей RTX 4070 Ti Super (менее мощная карта прошлого поколения). Vulkan-бэкенд whisper.cpp, наоборот, активно оптимизируется — в январе 2026 получил 12-кратное ускорение на встроенных GPU.
На практике это значит: на RTX 50-серии Handy с Vulkan сейчас быстрее OpenWhispr с CUDA. Типичная диктовка 30-60 секунд: Handy обрабатывает за 1-2 секунды, OpenWhispr — за 2-3. Оба комфортны, но разница ощутима. На более ранних картах (RTX 30xx, 40xx) CUDA по-прежнему впереди — так что рекомендация зависит от железа.
GigaAM, SuperWhisper и другие варианты

GigaAM v3 — модель от SberDevices, специально обученная на русском языке. На бумаге — SOTA для русского: по бенчмаркам разработчика, в разы точнее Whisper Large на русскоязычных датасетах. И это при 220 миллионах параметров против 1,55 миллиарда у Whisper Large — в 7 раз компактнее. Работает даже на CPU.
В Handy GigaAM добавили через PR #913. Я попробовал — и первое впечатление было: «Вообще даже не рядом с Whisper Large». Потом перетестировал внимательнее и пересмотрел: русский текст действительно быстро и качественно, сопоставимо с Whisper. И скорость реально впечатляет — надиктовываешь три абзаца, и текст появляется моментально, даже на Mac.
Но есть проблема: английские слова GigaAM ломает стабильно. Gemini превращается в «Jemni». Whisper Large — в «WisperLorge». Я прогнал одно и то же аудио 6 раз — после первого прогона модель стабильно выдавала «Jemni» каждый раз. Ещё растяжки типа «аааа» пишет прямо в текст.
Для чистого русского на машинах без мощной видеокарты — отличный выбор. Для IT-контекста, где английские термины неизбежны — пока не подходит. Модель молодая, обучена на 700 000 часах русской речи. Было бы супер иметь модель, заточенную под русский, которая при этом хорошо понимает вкрапления английского — ждём.
Параллельно тестировал ещё одного свежего кандидата — NVIDIA Canary 1B v2. Миллиард параметров, заявлена поддержка русского и английского, быстрая автопунктуация прямо из коробки.
Иногда она даёт прям вау-результат: русская речь с английскими вкраплениями, всё на своих местах, термины латиницей, падежи согласованы. Я сидел и думал: «Блин, может это реально тема, зачем мне весь огород с Whisper Large и CUDA».
А потом неизбежно вылезает кусок, где английские слова превратились во что-то очень странное кириллицей — как у GigaAM, только ещё и менее предсказуемо. Настроек для code-switching никаких: выберешь auto — русскую речь вообще игнорирует, выберешь русский — вязнет на английских терминах. Сам русский мне понравился: пунктуацию расставляет аккуратно и без всякого промпта, работает быстро. Хороший был челленджер, сходу не взял. Может, его можно дофайнтюнить под IT-контекст — пока руки не дошли.
SuperWhisper — приложение, которое рекомендует Karpathy.

Первое, что удивило после установки: при первом запуске играет музыка. В 2026 году. Ну ладно.
Само приложение выглядит аккуратно и продуманно. Под капотом — модели Whisper под собственными названиями:
| SuperWhisper | На самом деле | Параметры |
|---|---|---|
| Nano | Whisper Tiny | 39M |
| Fast | Whisper Base | 74M |
| Standard | Whisper Small | 244M |
| Pro | Whisper Medium / Turbo | 769-809M |
| Ultra | Whisper Large v3 | 1,55B |
После 15-минутного триала доступ к Ultra пропадает. Самая большая бесплатная модель — Standard. И знаете что? Она работает на удивление хорошо. Может быть, на 95% так же, как Large. Быстро, достаточно точно, чуть хуже с англицизмами. Большой разницы с Ultra я, честно, не заметил. Возможно, в SuperWhisper как-то дополнительно оптимизируют свои модели — промптят или файнтюнят — потому что когда я гонял Whisper Small и Medium напрямую через Handy или OpenWhispr, результат был заметно хуже.
Прайсинг: $8,5 в месяц или $85 в год за Pro. В российском App Store — 799 ₽ в месяц, 7 990 ₽ в год. То есть здесь, наоборот, через App Store дороже: $10 вместо $8,5 за месяц.
Есть баг: в терминале VS Code SuperWhisper не вставляет текст, а выводит его в своём окошке и засовывает в буфер обмена. Задокументированная проблема — workaround: режим Typing вместо Clipboard.
Работает на Windows, Mac, iPhone — но с оговорками. На Windows бывают нюансы с вставкой текста (тот же баг с VS Code). На iPhone в России, похоже, облачные модели работают только через VPN. Локальные модели запускаются без VPN, но паттерн работы другой: открывается отдельное приложение, в фоне работает нестабильно, текст вставляется неконсистентно. В итоге на iPhone SuperWhisper у меня не прижился.
Если Standard бесплатно — это очень хороший вариант для тех, кому не нужен топовый Large.
VRAM и экономика: когда локально имеет смысл
Whisper Large в VRAM — это прекрасно, но есть нюанс. На RTX 3080 с 10 ГБ видеопамяти модель занимала значительную часть. Когда я ещё пытался подключить вторую модель для text cleanup (Qwen3 4B) — 10 гигов забивались полностью. Вся видеокарта отведена под распознавание речи. Хочу подмонтировать видео — надо выключать этот софт, потом включать обратно.

Покупать видеокарту только ради голосового набора — точно не стоит. Но если у вас уже есть GPU с 8+ ГБ VRAM — это хороший способ сэкономить 8 000-10 000 ₽ в год на облачных подписках. Причём не обязательно что-то топовое: Whisper Large занимает около 6 ГБ видеопамяти, и если карта выделена чисто под эту задачу, хватит даже 6 ГБ.
После апгрейда на 5070 Ti ситуация изменилась. Когда апгрейдил, читал про варианты оставить старую 3080 в системе и крутить на ней модель отдельно. В принципе, это возможно. Но решил, что мне это не нужно, и лучше получить деньги за старую карту. Если же у вас лежит без дела какая-нибудь карта с 6-8 ГБ — вполне рабочий вариант выделить её под Whisper.
На 5070 Ti Whisper Large работает в фоне постоянно. Могу параллельно монтировать видео, запускать рендер — на всё хватает. А после того, как промпт решил проблему пунктуации, вторая модель для text cleanup больше не нужна — VRAM свободнее.
При этом, судя по скорости развития индустрии, требования к железу будут снижаться. GigaAM уже в 7 раз компактнее Whisper Large и работает на CPU, Distil-Whisper даёт 99% качества в 6 раз быстрее. Думаю, через год-два появятся модели, которые будут давать сопоставимое с Whisper Large качество на обычном процессоре или встроенной видеокарте — без дискретного GPU.
Mac, iPhone и мультиплатформенность

Про Mac на Apple Silicon — OpenWhispr и Handy оба неплохо работают с GPU-ускорением. На M4 Pro (14-ядерный) Whisper Large даёт вполне комфортную скорость. Handy буквально на днях выкатил релиз с улучшенным GPU-ускорением для чипов Apple, и после этого Whisper Large стал достойно работать и там. На обычном M4 у жены — прям на грани. Разница ощутимая, кому-то будет комфортно, кому-то слишком долго ждать.
На iPhone — WisprFlow встраивается как отдельная клавиатура, что уже само по себе не очень удобно. Нужно переключить язык, чтобы найти кнопку включения, потом вызывается приложение, нужно свайпнуть обратно. Дополнительное трение. Но с точки зрения качества расшифровки — вариант, наверное, лучший на iPhone.
SuperWhisper на iPhone — с оговорками. В России облачные модели требуют VPN, локальные работают, но UX другой: открывается отдельное приложение, фоновая запись нестабильна. Плюс если не задать русский язык явно, приложение часто пытается перевести речь на английский.
Важный момент для телефона: у WisprFlow есть бесплатный план до 2 000 слов в месяц, SuperWhisper на бесплатной модели Standard работает без ограничений. Мне для телефонного использования хватает с запасом.
Что выбрать: сводная таблица
| Handy | OpenWhispr | SuperWhisper | WisprFlow | SpeakFlow | |
|---|---|---|---|---|---|
| Цена | Бесплатно | Бесплатно (локально) | Бесплатно (Standard) / от $8,5/мес | от 750 ₽/мес | от 690 ₽/мес |
| Open source | Да | Да | Нет | Нет | Нет |
| Где работает | Локально | Локально / облако | Локально / облако | Облако | Облако |
| Windows | Да | Да | Да | Да | Да |
| Mac | Да | Да | Да | Да | Нет |
| iPhone | Нет | Нет | Да | Да | Нет |
| CUDA (NVIDIA) | Нет (Vulkan) | Да | Нет | — | — |
| AMD (Vulkan) | Да | Нет | Нет | — | — |
| Whisper Large | Да | Да | Да (Ultra, платно) | — | — |
| GigaAM v3 | Да | Нет | Нет | Нет | Нет |
| Микс языков | Зависит от модели | Отлично (Large) | Хорошо (Ultra) | Хорошо | Средне |
Мой выбор: OpenWhispr + Whisper Large + CUDA на десктопе. На Mac тоже Whisper Large — M4 Pro тянет. Если бы не тянул — выбирал бы между Whisper Turbo и GigaAM, склоняясь к Turbo. Для телефона — WisprFlow (бесплатный план до 2 000 слов/мес). SuperWhisper на десктопе хорош бесплатно на Standard — это уже 95% качества, но на iPhone и Windows есть шероховатости.
Транскрибация аудио и видео: та же технология

Всё, о чём мы говорили — модели, промпт для пунктуации, VRAM, выбор между Turbo и Large — применимо и к транскрибации записей. Расшифровка аудиофайла, извлечение текста из видео, транскрибация записи встречи — это та же задача: речь в текст. Просто не в реальном времени.
Некоторые приложения уже предлагают это из коробки. OpenWhispr в последних версиях добавил режим транскрибации встреч — умеет отслеживать начало созвона в Zoom и автоматически записывать. Для интервью и подкастов есть WhisperX — он добавляет пословные таймстемпы и определяет, кто говорит.
Отдельно стоит упомянуть Vibe — бесплатное open-source приложение, заточенное именно под транскрибацию файлов. Локальные модели, простой интерфейс, активное сообщество. Для диктовки Vibe тоже формально умеет, но пока не хватает базовых удобств: нет звукового сигнала при начале и конце записи, нет визуального индикатора, нет выбора режима шортката (нажал-говоришь-нажал vs удерживаешь кнопку). Для расшифровки файлов — рекомендую попробовать.
А если хочется полного контроля — можно собрать свой скрипт. Попросите Claude Code или Cursor настроить папку, куда кладёте аудио или видео: скрипт вытащит звуковую дорожку и прогонит через Whisper. Все выводы про модели из этой статьи работают и здесь.
Что дальше
Whisper Large v3 вышел в ноябре 2023 года. Turbo — в сентябре 2024. С тех пор — тишина. OpenAI не выпускали Whisper v4 и, похоже, движутся в другую сторону: выпустили GPT-4o-transcribe — проприетарную облачную модель, доступную только через API. Для локального использования она бесполезна.
Но вокруг Whisper выросла целая экосистема независимых проектов — и она живёт и развивается без OpenAI:
- whisper.cpp — полная переписка Whisper на C++, автор — Георги Герганов (он же создал llama.cpp). Работает без Python, запускается на чём угодно — от десктопа до телефона. Именно whisper.cpp используется под капотом в OpenWhispr. В январе 2026 получил 12-кратное ускорение на встроенных GPU через Vulkan.
- faster-whisper — другой подход к ускорению: берёт оригинальную модель Whisper и конвертирует в оптимизированный формат (CTranslate2) с квантизацией. Примерно в 4 раза быстрее оригинала при том же качестве. Активно поддерживается.
- Distil-Whisper — проект Hugging Face: через дистилляцию создают уменьшенные версии Whisper, которые работают в 6 раз быстрее при 99% точности. Правда, лучше всего работает на английском.
- WhisperX — надстройка, которая добавляет то, чего в базовом Whisper нет: пословные таймстемпы и определение, кто говорит. Полезно для транскрибации интервью и подкастов.
GigaAM v3 от Сбера я подробно разобрал выше. Parakeet V3 от NVIDIA тоже гонял — и видел, как гоняли другие: русский работает, но на миксе с английским результаты средние. Canary 1B v2 — та же история, см. разбор выше.
В конце марта 2026 вышла ещё одна свежая модель — Cohere Transcribe. 2B параметров, Conformer-архитектура, Apache 2.0, средний WER 5,42%, топ Open ASR Leaderboard среди открытых моделей. По меркам индустрии — громкий релиз. Но русского среди 14 поддерживаемых языков нет. Возможно, политика; возможно, просто приоритеты рынка.
Эпоха, когда одна монолитная модель от OpenAI была безальтернативным стандартом, подходит к концу. Whisper и его наследие — открытый код, форки, коммьюнити-проекты — живут и будут жить ещё долго. А свежие SOTA-релизы вроде Cohere Transcribe русскоязычному пользователю без русского не помогают.
Для русского айтишника и вайб-кодера надежда — на то, что уже есть, и на то, что мы делаем сами. С одной стороны — докрутка иностранных моделей: fine-tuning, форки, pull requests, коммьюнити вокруг Whisper. С другой — собственные модели под русский, обученные с нуля. Хочется, чтобы таких проектов появлялось больше.
Отдельное спасибо SberDevices за GigaAM и движение в правильном направлении. Под мой сценарий с миксом языков модель пока не подходит, но результат на чистом русском у ребят правда впечатляющий. С удовольствием перейду на неё, как только научится работать с вкраплениями английского.
Частые вопросы
Какая модель лучше распознаёт русскую речь — Whisper или GigaAM?
GigaAM v3 от Сбера показывает лучший WER на чистом русском — по бенчмаркам разработчика, в разы точнее Whisper. Но если в речи есть английские слова — Whisper Large v3 точнее, потому что GigaAM стабильно ломает английские вкрапления. Хотя лучший выбор для русско-английского микса — уже не Large v3: по моему бенчмарку 23 моделей его обходят Breeze-ASR и Whisper Turbo.
Можно ли использовать голосовой ввод бесплатно и без интернета?
Да. Handy и OpenWhispr — бесплатные open-source приложения, которые работают полностью локально. Для комфортной скорости нужна видеокарта с поддержкой CUDA или Vulkan (от 6 ГБ VRAM).
Чем отличается Whisper Large v3 от Turbo?
Turbo заметно быстрее (в 3–6 раз в зависимости от реализации) и с пунктуационным промптом обходит Large v3 и по распознаванию слов, и по английским терминам — это показал мой бенчмарк 23 моделей. Нюанс: без промпта Turbo почти не ставит знаки препинания, а Large v3 ставит их сам.
Как добавить знаки препинания в распознанный текст?
Whisper поддерживает промптинг — короткий текст-пример с разнообразными знаками препинания, который «прогревает» модель. Это даёт корректную пунктуацию в 99%+ случаев.
Сколько VRAM нужно для Whisper Large v3?
Whisper Large v3 занимает около 6 ГБ VRAM. На карте с 10 ГБ (RTX 3080) работает, для обычных задач места хватает, но GPU-heavy вещи вроде монтажа или рендера параллельно уже тесновато. На 16 ГБ (RTX 5070 Ti) — комфортно, хватает на всё.
Что ещё пробовали, кроме Whisper и GigaAM?
Canary 1B v2 от NVIDIA и Cohere Transcribe — обе свежие, обе амбициозные. Canary иногда даёт отличный результат на русско-английском миксе, но стабильно срывается на английских словах, превращая их в странную кириллицу, и не имеет настроек для code-switching. Cohere Transcribe русский вообще не поддерживает — его нет в списке 14 языков. По итогам большого бенчмарка я с Large v3 в итоге ушёл: лучший open-source на русском IT-миксе — Breeze-ASR, а из самих Whisper лучше всех Turbo.




